梯度裁剪
作者: Mingyan Jiang
前置教程
相关论文
引言
为了加快训练过程和寻求全局最优以获得更好的性能,越来越多的学习率调度器被提出。人们通过控制学习率来调整训练中的下降速度。这使得梯度向量在每一步都能更好地统一。在这种情况下,下降速度可以按预期被控制。 因此,梯度裁剪,一种可以将梯度向量归一化,以将其限制在统一长度的技术,对于那些希望模型性能更好的人来说是不可或缺的。
在使用 Colossal-AI 时,你不必担心实现梯度剪裁,我们以一种有效而方便的方式支持梯度剪裁。你所需要的只是在你的配置文件中增加一个命令。
为什么应该使用 Colossal-AI 中的梯度裁剪
我们不建议用户自己编写梯度剪裁,因为朴素的梯度剪裁在应用张量并行、流水线并行、MoE 等功能时可能会失败。
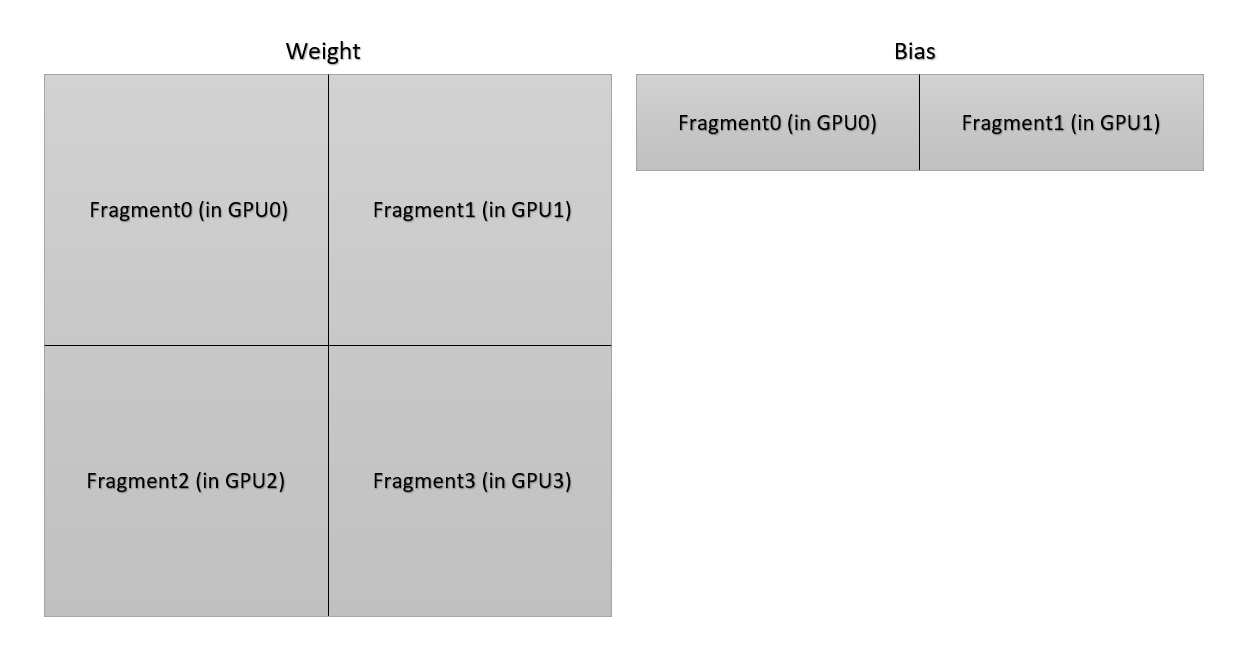
根据下图,每个 GPU 只拥有线性层中权重的一部分参数。为了得到线性层权重的梯度向量的正确范数,每个 GPU 中的每个梯度向量的范数应该相加。更复杂的是,偏置的分布不同于权重的分布。通信组在求和运算中有所不同。
(注: 这种情况是旧版本的 2D 并行,在代码中的实现是不一样的。但这是一个很好的例子,能够说明在梯度剪裁中统一所有通信的困难。)
不用担心它,因为 Colossal-AI 已经为你处理好。
使用
要使用梯度裁剪,只需在使用booster注入特性之后,调用optimizer的clip_grad_by_norm或者clip_grad_by_value函数即可进行梯度裁剪。
实例
下面我们将介绍如何使用梯度裁剪,在本例中,我们将梯度裁剪范数设置为1.0。
步骤 1. 在训练中导入相关库
创建train.py并导入相关库。
import os
from pathlib import Path
import torch
from torchvision import transforms
from torchvision.datasets import CIFAR10
from torchvision.models import resnet34
from tqdm import tqdm
import colossalai
from colossalai.booster import Booster
from colossalai.booster.plugin import TorchDDPPlugin
from colossalai.logging import get_dist_logger
from colossalai.nn.lr_scheduler import CosineAnnealingLR
步骤 2. 初始化分布式环境
我们需要初始化分布式环境. 为了快速演示,我们使用launch_from_torch. 您可以参考 Launch Colossal-AI
colossalai.launch_from_torch(config=dict())
logger = get_dist_logger()
步骤 3. 创建训练组件
构建你的模型、优化器、损失函数、学习率调整器和数据加载器。注意数据集的路径从环境变量DATA获得。你可以通过 export DATA=/path/to/data 或 Path(os.environ['DATA'])在你的机器上设置路径。数据将会被自动下载到该路径。
# define training hyperparameters
NUM_EPOCHS = 200
BATCH_SIZE = 128
GRADIENT_CLIPPING = 0.1
# build resnet
model = resnet34(num_classes=10)
# build dataloaders
train_dataset = CIFAR10(root=Path(os.environ.get('DATA', './data')),
download=True,
transform=transforms.Compose([
transforms.RandomCrop(size=32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
]))
# build criterion
criterion = torch.nn.CrossEntropyLoss()
# optimizer
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
# lr_scheduler
lr_scheduler = CosineAnnealingLR(optimizer, total_steps=NUM_EPOCHS)
步骤 4. 注入梯度裁剪特性
创建TorchDDPPlugin对象并初始化Booster, 使用booster注入相关特性。
plugin = TorchDDPPlugin()
booster = Booster(plugin=plugin)
train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
model, optimizer, criterion, train_dataloader, lr_scheduler = booster.boost(model,optimizer, criterion,train_dataloader, lr_scheduler)
步骤 5. 使用booster训练
使用booster进行训练。
# verify gradient clipping
model.train()
for idx, (img, label) in enumerate(train_dataloader):
img = img.cuda()
label = label.cuda()
model.zero_grad()
output = model(img)
train_loss = criterion(output, label)
booster.backward(train_loss, optimizer)
optimizer.clip_grad_by_norm(max_norm=GRADIENT_CLIPPING)
optimizer.step()
lr_scheduler.step()
ele_1st = next(model.parameters()).flatten()[0]
logger.info(f'iteration {idx}, loss: {train_loss}, 1st element of parameters: {ele_1st.item()}')
# only run for 4 iterations
if idx == 3:
break
步骤 6. 启动训练脚本
你可以使用以下命令运行脚本:
colossalai run --nproc_per_node 1 train.py