3D 张量并行
作者: Zhengda Bian, Yongbin Li
前置教程
示例代码
相关论文
3D 张量并行 是一种将神经网络模型的计算并行化,以期望获得最佳通信成本优化的方法。
我们还是以线性层 Y=XA 为例。
给定 P=q×q×q 个处理器(必要条件), 如 q=2, 我们把输入 X 和权重 A 划分为
⎣⎢⎢⎢⎡X000X010X100X110X001X011X101X111⎦⎥⎥⎥⎤ and [A000A100A001A101A010A110A011A111] respectively, 其中每个 Xijl 和 Alji 都被存储在处理器 (i,j,l) 上, 如下图所示。
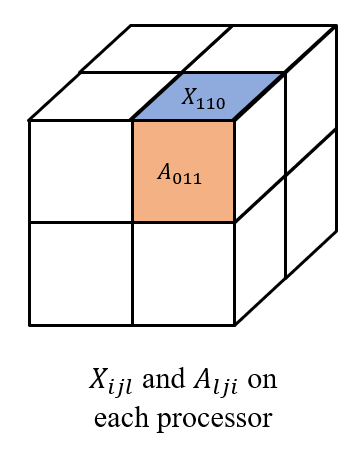
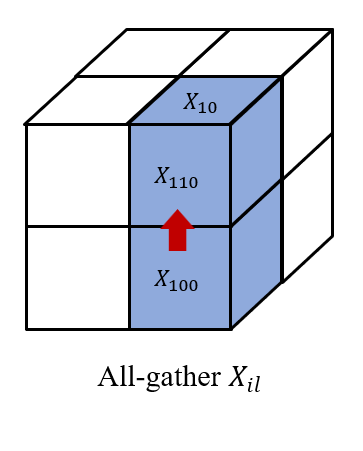
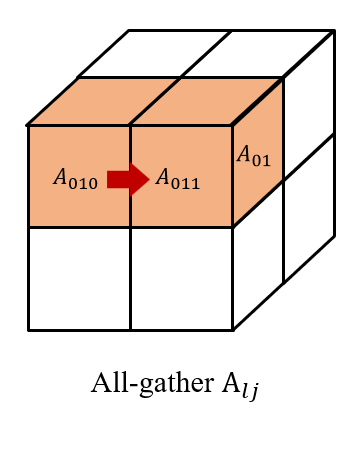
然后我们在 (i,0...q,l) 上收集 Xijl, 以及在(0...q,j,l) 上收集 Alji。
因此,我们在每个处理器 (i,j,l) 上都有 Xil 和 Alj 以获得 XilAlj。
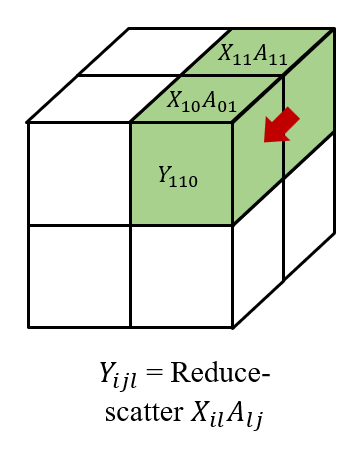
最后,我们在 (i,j,0...q) 对结果进行 reduce-scatter 得到 Yijl, 形成
Y=⎣⎢⎢⎢⎡Y000Y010Y100Y110Y001Y011Y101Y111⎦⎥⎥⎥⎤. 我们还需要注意,在后向传播中, 我们需要 all-gather 梯度 Yijl˙, 然后 reduce-scatter 梯度 Xil˙=Yij˙AljT and Alj˙=XilTYij˙。
给定 P=q×q×q 个处理器, 我们展现理论上的计算和内存成本,以及基于环形算法的3D张量并行的前向和后向的通信成本。
| 计算 | 内存 (参数) | 内存 (activations) | 通信 (带宽) | 通信 (时延) |
|---|
| O(1/q3) | O(1/q3) | O(1/q3) | O(6(q−1)/q3) | O(6(q−1)) |
ColossalAI的最新版本还暂不支持3D张量并行,但3D张量并行的功能会在未来的版本被集成入Shardformer中。关于Shardformer的原理和用法细节请参考当前目录下的Shardformer文档。
对于老版本ColossalAI的用户,3D张量并行的用法请参考ColossalAI-Examples - 3D Tensor Parallelism。